Ditto 
Building Digital Twins of Articulated Objects from Interaction
Zhenyu Jiang Cheng-Chun Hsu Yuke Zhu
The University of Texas at Austin
CVPR 2022 Oral Presentation
Paper | Code
|
Digitizing physical objects into the virtual world has the potential to unlock new research and applications in embodied AI and mixed reality. This work focuses on recreating interactive digital twins of real-world articulated objects, which can be directly imported into virtual environments. We introduce Ditto to learn articulation model estimation and 3D geometry reconstruction of an articulated object through interactive perception. Given a pair of visual observations of an articulated object before and after interaction, Ditto reconstructs part-level geometry and estimates the articulation model of the object. We employ implicit neural representations for joint geometry and articulation modeling. Our experiments show that Ditto effectively builds digital twins of articulated objects in a category-agnostic way. We also apply Ditto to real-world objects and deploy the recreated digital twins in physical simulation. |
Problem Definition
|
A digital twin is a virtual representation that serves as the real-time digital counterpart of a physical object or process[1]. Digital twins are commonly represented in standard 3D formats, such as URDF[2], such that they can be imported into physics engines. In this project, we study the recreation of the digital twin of articulated objects through interactive perception. Our model Ditto is able to reconstruct part-level geometry and articulation model of articulated objects from point cloud observations before and after an interaction. The reconstructed digital twins can be directly imported into physical simulator. |
Ditto Architecture
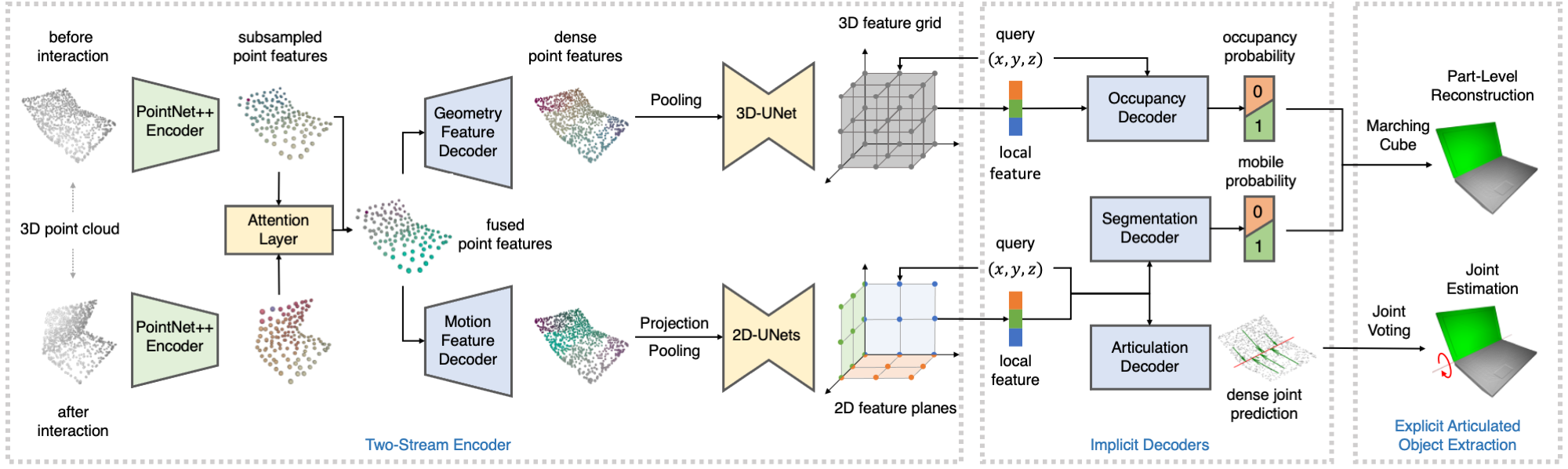 |
| The inputs are point cloud observations before and after interaction. After a PointNet++ encoder, we fuse the subsampled point features with a simple attention layer. Then we use two independent decoders to propagate the fused point features into two sets of dense point features, for geometry reconstruction and articulation estimation separately. We construct feature grid/planes by projecting and pooling the point features, and query local features from the constructed feature grid/planes. Conditioning on local features, we use different decoders to predict occupancy, segmentation and joint parameters with respect to the query points. |
Reconstruction Results
|
We show qualitative results on the Shape2Motion dataset. Ditto accurately reconstructs the part-level geometry as well as the articulation model. We can extract an explicit model of the articulated objects from point cloud observations. |
Real World Experiment
|
We tested Ditto on real world objects. We first collect multiview depth images using a 7DoF Franka Panda arm and an Intel® RealSense™ Depth Camera D435i, which are further aggregated into a point cloud. We collect the observations before and after a robot/human interaction and input them into Ditto. Ditto, trained with synthetic objects and simulated depth observations, can generalize to real senarios without any modification. |
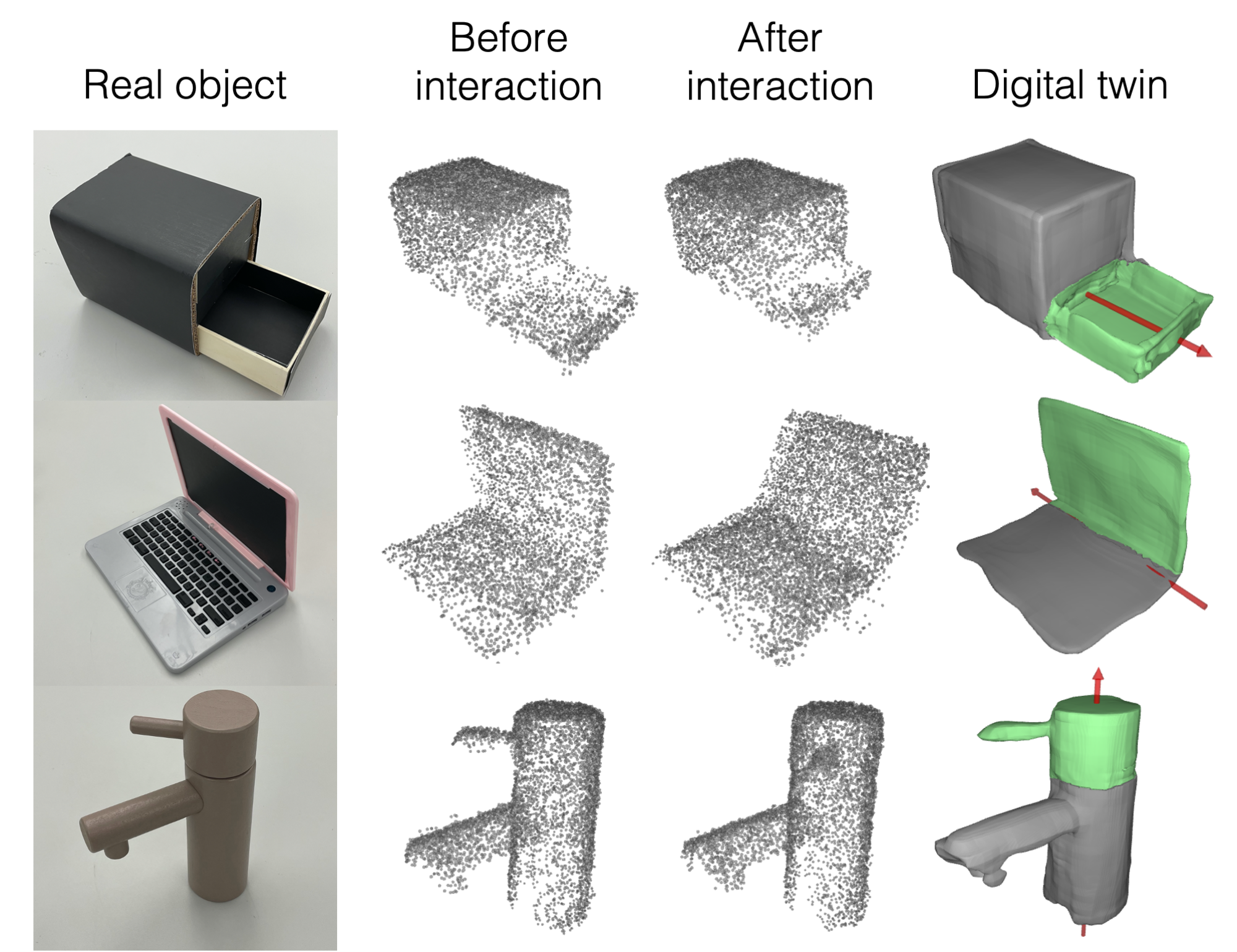 |
From Real World to Simulation and Back
|
We demonstrate one application of Ditto, where we recreate the digital twin of a faucet, directly spawn the digital twin in a physical simulation environment (robosuite), manipulate the faucet with the robot arm in simulation and transfer the manipulation action to the real world. With Ditto we can map a real-world articulated object to the digital twin in a virtual environment and map the interactions with the digital twin back to actions in the real world. |
Citation
|