 Doduo: Dense Visual Correspondence
Doduo: Dense Visual Correspondence
from Unsupervised Semantic-Aware Flow
Zhenyu Jiang Hanwen Jiang Yuke Zhu
The University of Texas at Austin
ICRA 2024
Paper | Code | Huggingface Model
|
Dense visual correspondence plays a vital role in robotic perception. This work focuses on establishing the dense correspondence between a pair of images that captures dynamic scenes undergoing substantial transformations. We introduce Doduo to learn general dense visual correspondence from in-the-wild images and videos without ground truth supervision. Given a pair of images, it estimates the dense flow field encoding the displacement of each pixel in one image to its corresponding pixel in the other image. Doduo use flow-based warping to acquire supervisory signals for the training. Incorporating semantic priors with self-supervised flow training, Doduo produces accurate dense correspondence robust to the dynamic changes of the scenes. Trained on an in-the-wild video dataset, Doduo illustrates superior performance on point-level correspondence estimation over existing self-supervised correspondence learning baselines. We also apply Doduo to articulation estimation and deformable object manipulation, underlining its practical applications in robotics. |
Video
Point Correspondence
|
Explore point correspondences generated by Doduo with our interactive demo. Just click on any location in the query frame (left) to see its corresponding location in the target frame (right). Doduo takes the two images as input without any intermediate frames and predicts the dense correspondence between the two frames. |




|
Articulation Estimation
|
We use Doduo to predict dense visual correspondence between two RGBD frames of an articulated object undergoing articulated motion. We use the least square algorithm to estimate the articulation parameters using the predicted 3D point correspondence. |
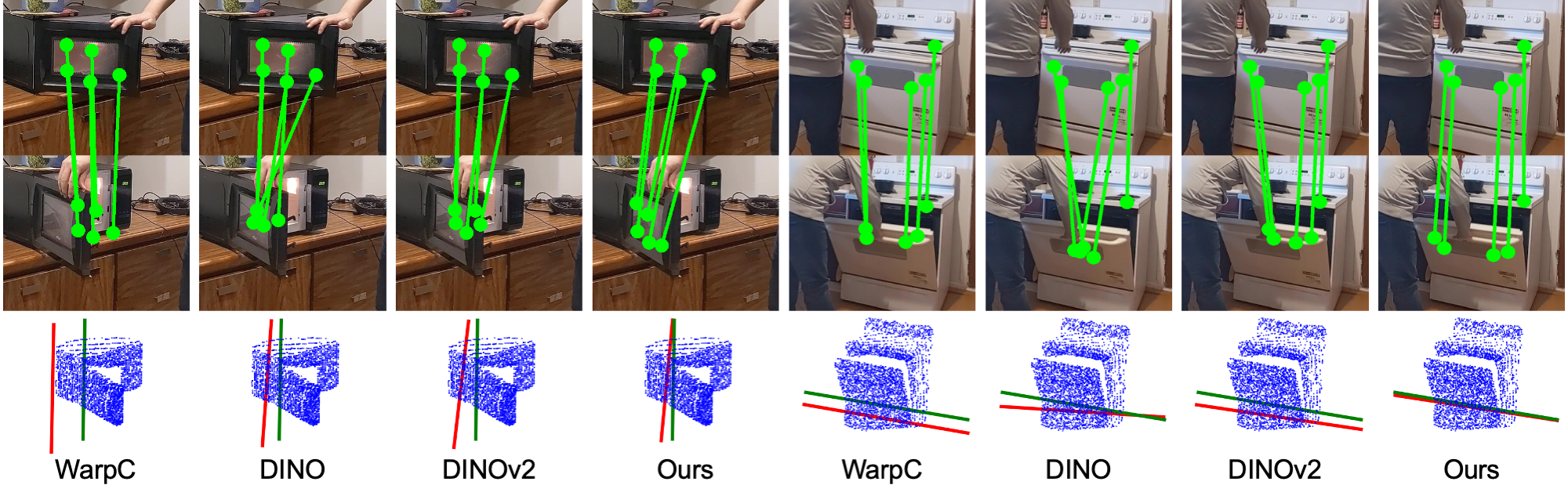 |
Goal-Conditioned Object Manipulation
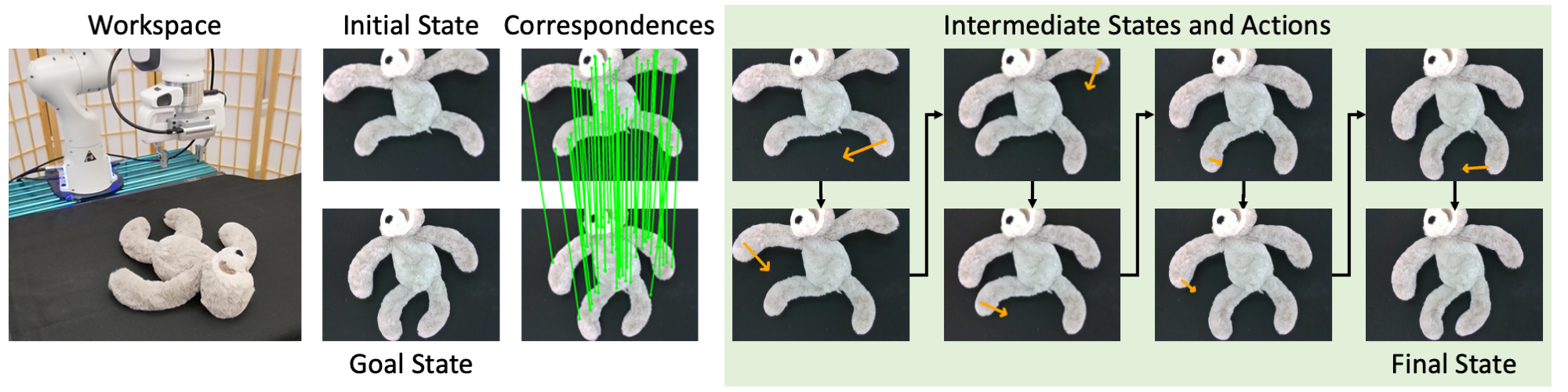 |
|
We apply Doduo to goal-conditioned object manipulation. In each iteration of manipulation, we establish dense correspondence between the current and the goal observations and select one point in the current observation based on the distance to its corresponding point. Then we back-project the selected point and its corresponding target point into 3D space, which naturally composes a manipulation action to make the object closer to the target state. Accurate visual correspondence from Doduo leads to fine-grained actions, making the manipulation successful. |
Citation
|