Few-View Object Reconstruction
with Unknown Categories and Camera Poses
Hanwen Jiang Zhenyu Jiang Kristen Grauman Yuke Zhu
The University of Texas at Austin
3DV 2024 (Oral)
Paper | Code
|
While object reconstruction has made great strides in recent years, current methods typically require densely captured images and/or known camera poses, and generalize poorly to novel object categories. To step toward object reconstruction in the wild, this work explores reconstructing general real-world objects from a few images without known camera poses or object categories. The crux of our work is solving two fundamental 3D vision problems — shape reconstruction and pose estimation — in a unified approach. Our approach captures the synergies of these two problems: reliable camera pose estimation gives rise to accurate shape reconstruction, and the accurate reconstruction, in turn, induces robust correspondence between different views and facilitates pose estimation. Our method FORGE predicts 3D features from each view and leverages them in conjunction with the input images to establish cross-view correspondence for estimating relative camera poses. The 3D features are then transformed by the estimated poses into a shared space and are fused into a neural radiance field. The reconstruction results are rendered by volume rendering techniques, enabling us to train the model without 3D shape ground-truth. Our experiments show that FORGE reliably reconstructs objects from five views. Our pose estimation method outperforms existing ones by a large margin. The reconstruction results under predicted poses are comparable to the ones using ground-truth poses. The performance on novel testing categories matches the results on categories seen during training. |
Real-World Demo
Using Online Product Data
Using iPhone-captured Data
|
We tested FORGE on real-world data captured by iPhone. We used three images as inputs of FORGE and compared it with COLMAP which uses dense inputs. FORGE reliably reconstructed the objects from novel categories even though the lighting condition, image capturing stratergy and camera intrinsics are different from training. |
Problem Definition
|
3D reconstruction is the process of capturing the shape and appearance of real objects[1]. Reconstruction results can be represented by explicit 3D representations, e.g., mesh, voxel and point cloud, or implicit representations, like the neural radiance field. In this project, we study the problem of object reconstruction from a few RGB observations with unknown camera poses and unknown object category. Our method Few-view Object Reconstruction that Generalize (FORGE) estimates the relative camera poses of the input views and extractes per-view 3D featrues. The featrues are fused based on the predicted poses to predict a neural volume, encoding the radiance field. The reconstruction results can be produced to 2D by using volume rendering techniques. |
FORGE Architecture
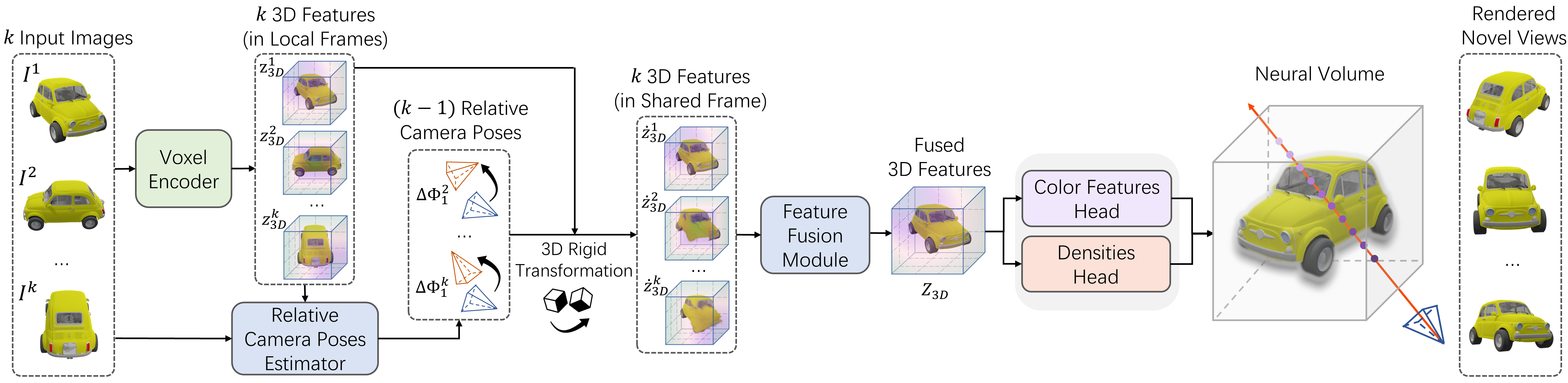 |
| The inputs are a few observations, e.g., five views, of the object. FORGE uses a voxel encoder to extract per-view 3D features, which are defined in their corresponding camera's local frame. Then FORGE predicts the relative camera poses of the input views using the 3D features and 2D raw observations as inputs. The 3D features are transformed into a shared reconstruction space using the rigid transformation computed by the relative camera poses. The features are fused to predict a neural volume that encodes the radiance field. We use volume rendering techniques to render the reconstruction results. FORGE is trained without 3D shape ground-truth. |
Reconstruction Results
|
To evaluate the generalization ability of FORGE, we propose a new datasets containing both training and novel object categories. The camera poses are randomly sampled. When using ground-truth camera poses, FORGE outperforms previous SOTA PixelNeRF by 2 dB PSNR with 3000 times faster inference speed. We use 5 views as inputs and evaluate the performance on another 5 novel views, where we show 2 of them. 
|
Reconstructing Objects in Training Categories
|
We show reconstruction results using predicted camera poses on 13 training categories from ShapeNet with 5 input images. FORGE accuratly predicts the shape and appearance of objects. |
Zero-shot Generalization to Novel Categories
|
We show zero-shot generalization results using predicted camera poses on 10 novel categories from ShapeNet with 5 input images. FORGE reliably reconstructs objects from novel categories with a small PSNR gap of 0.8 dB compared with results on training categories. |
Zero-shot Generalization to Real Objects
|
FORGE trained on ShapeNet objects generalize well on real objects from Google Scanned Object dataset. All objects are from novel categories with diverse geometry and texture. FORGE using predicted poses demonstrates better reconstruction quality than PixelNeRF with ground-truth poses. |
Voxel Reconstruction
|
We get voxel reconstruction results by simply thresholding the predicted density of neural volume. The results shows the strong ability of FORGE for capturing 3D geometry even though it is trained without 3D shape ground-truth.  |
Pose Estimation Results
|
We show relative camera pose estimation results on objects from both training and novel categories. Predicted and ground-truth poses are shown in the same color with colored and white faces. FORGE achieves 5 degree and 10 degree pose errors on training and novel categories, reducing the errors by more than 60% compared with previous SOTA. |
Citation
|