Ditto in the House: Building Articulated Models of Indoor Scenes through Interactive Perception
Cheng-Chun Hsu Zhenyu Jiang Yuke Zhu
The University of Texas at Austin
ICRA 2023
Paper | Code
|
Virtualizing the physical world into virtual models has been a critical technique for robot navigation and planning in the real world. To foster manipulation with articulated objects in everyday life, this work explores building articulation models of indoor scenes through a robot's purposeful interactions in these scenes. Prior work on articulation reasoning primarily focuses on siloed objects of limited categories. To extend to room-scale environments, the robot has to efficiently and effectively explore a large-scale 3D space, locate articulated objects, and infer their articulations. We introduce an interactive perception approach to this task. Our approach, named Ditto in the House, discovers possible articulated objects through affordance prediction, interacts with these objects to produce articulated motions, and infers the articulation properties from the visual observations before and after each interaction. It tightly couples affordance prediction and articulation inference to improve both tasks. We demonstrate the effectiveness of our approach in both simulation and real-world scenes. |
Problem Definition

|
|
We explore the problem of building an articulation model of an indoor scene populated with articulated objects. An articulated object consists of multiple parts, and their connecting joints constrain the relative motion between each pair of parts. Scene-level articulated model informs the robot where the interactable regions are and gives more context about how to interact with the objects. |
Framework
 |
| Our approach consists of two stages --- affordance prediction and articulation inference. During affordance prediction, we pass the static scene point cloud into the affordance network and predict the scene-level affordance map. By applying point non-maximum suppression (NMS), we extract the interaction hotspots from the affordance map. Then, the robot interacts with the object based on those contact points. During articulation inference, we feed the point cloud observations before and after each interaction into the articulation model network to obtain articulation estimation. By aggregating the estimated articulation models, we build the articulation models of the entire scene. |
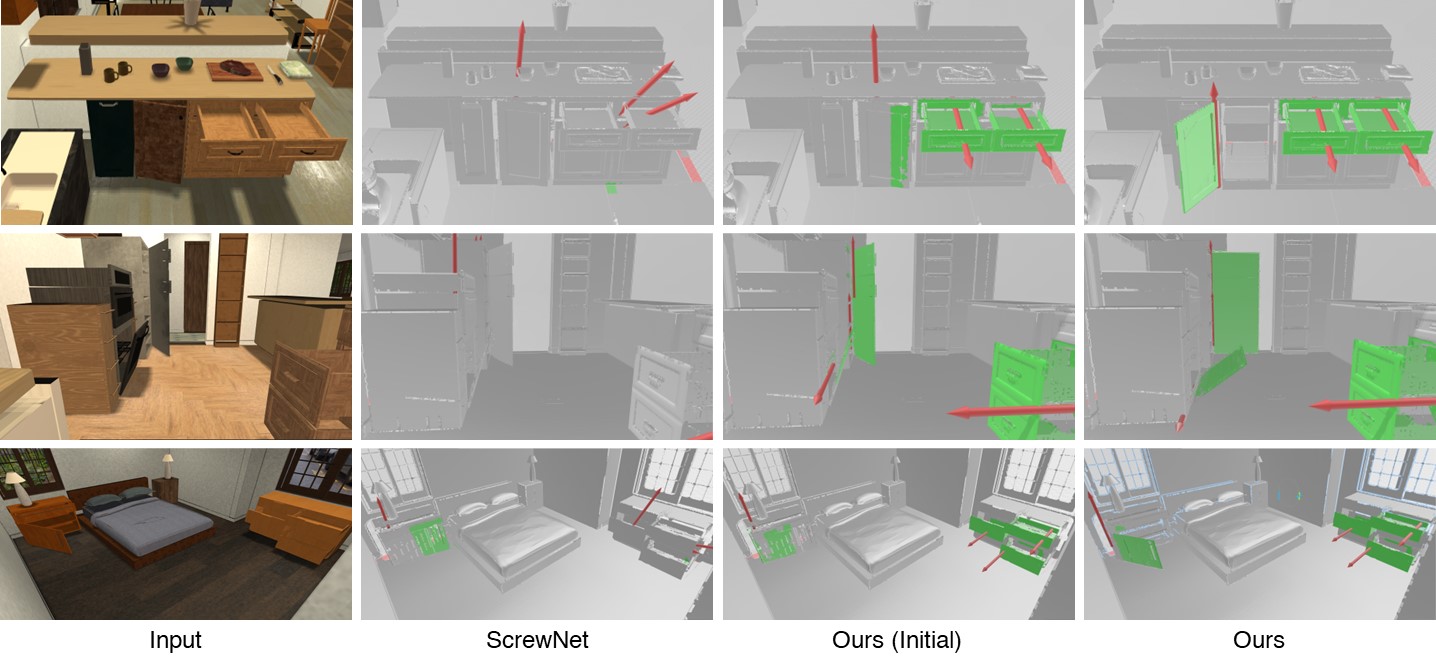
Reconstruction Results
|
We show qualitative results on the iGibson scenes. Our model first opens the cabinet to a larger degree and reveals more previously occluded surfaces. With the new observation with more significant object state change, our refined model can predict more accurate part segmentation and joint parameters. |
|
Real World Experiment
|
We evaluate our method in a real-world household scene. We use the LiDAR and camera of an iPhone 12 Pro to recreate the scene in a 3D scan, rather than using a physical robot. We predict interaction hotspots and interact with the objects at these hotspots with our own hands. We then collect novel observations and run our approach to build the scene-level articulation model. The videos show that our approach can be applied to the real scenario without any modification and reconstruct an accurate articulation model of the scene. |
Kitchen
Office
Citation
|