MUTEX: Learning Unified Policies from Multimodal Task Specifications
Rutav Shah Roberto Martín-Martín* Yuke Zhu*
* Equal Advising
The University of Texas at Austin
Paper | Dataset | Code | BibTeX
Conference on Robot Learning (CoRL), 2023
|
Humans use different modalities, such as speech, text, images, videos, etc., to communicate their intent and goals with teammates. For robots to become better assistants, we aim to endow them with the ability to follow instructions and understand tasks specified by their human partners. Most robotic policy learning methods have focused on one single modality of task specification while ignoring the rich cross-modal information. We present MUTEX, a unified approach to policy learning from multimodal task specifications. It trains a transformer-based architecture to facilitate cross-modal reasoning, combining masked modeling and cross-modal matching objectives in a two-stage training procedure. After training, MUTEX can follow a task specification in any of the six learned modalities (video demonstrations, goal images, text goal descriptions, text instructions, speech goal descriptions, and speech instructions) or a combination of them. We systematically evaluate the benefits of MUTEX in a newly designed dataset with 100 tasks in simulation and 50 tasks in the real world, annotated with multiple instances of task specifications in different modalities, and observe improved performance over methods trained specifically for any single modality. |
MUTEX Overview
 |
|
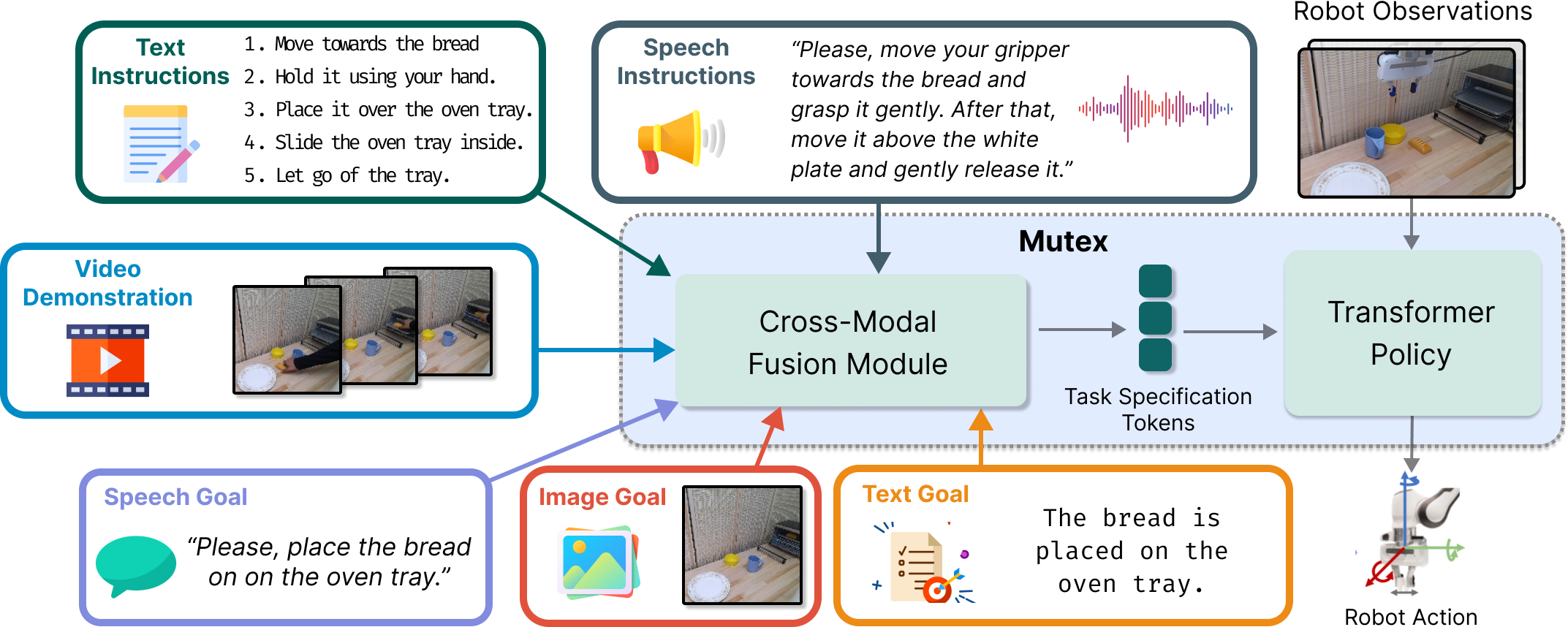
We introduce MUTEX, a unified policy that learns to perform tasks based on task specifications in multiple modalities: image, video, text, and speech, in the form of instructions and goal descriptions. Based on a novel two-stage cross-modal representation learning procedure, MUTEX learns to leverage information across modalities to become more capable at executing tasks specified by any single modality than methods trained specifically for each one. |
MUTEX Architecture
|
Task specifications in each modality are encoded with pretrained modality-specific encoders. During the first stage of training, one or more of these modalities are randomly selected and masked before being passed to projection layers and input to MUTEX's transformer encoder. The resultant tokens are combined with observation tokens through N blocks of self- and cross-attention layers. The hidden state of the encoder is passed to MUTEX's transformer encoder that is queried for actions (behavior learning loss) and the masked features and tokens (masked modeling loss), promoting action-specific cross-modal learning. In the second stage of training, all modalities are enriched with information from video features through a cross-modal matching loss. At test time, observations and a task specification of one modality are provided, based on which MUTEX predicts closed-loop actions to achieve the task. |
Simulation and Real-World Results

|

|
|
We demonstrate that a policy that can execute task specified by multiple modalities generalizes better than a policy that can only execute tasks specified by any-single modality. The results of our evaluation in simulation (each method averaged over 6000 evaluation trajectories) and the real world (each method averaged over 50 evaluation trajectories) are summarized in the figure above. In both cases, we observe a significant improvement from using our unified policy MUTEX compared to modality-specific models indicating that the cross-modal representation learning procedure from MUTEX is able to leverage more information from other modalities. |
Real World Demonstration
|
|
MUTEX can execute tasks specified by humans in any of the six modalities: human video demonstrations, text instructions, text goals, speech instructions, speech goals, and image goals. To demonstrate the capabilities and robustness of MUTEX, we qualitatively evaluate MUTEX in the real world when a human specifies the tasks live through one of the modalities. |
[Press Reload to change the tasks]
MUTEX Dataset Visualization
|
We provide a dataset comprising 100 simulated tasks based on LIBERO-100 and 50 real-world tasks, annotated with 50 and 30 demonstrations per task (row following Task Name), respectively. We annotate each task with eleven alternative task specifications in each of the six following modalities (rows from top to bottom): video demonstration, image goal, text goal, text instructions, speech goal, and speech instructions. |
BibTeX
|