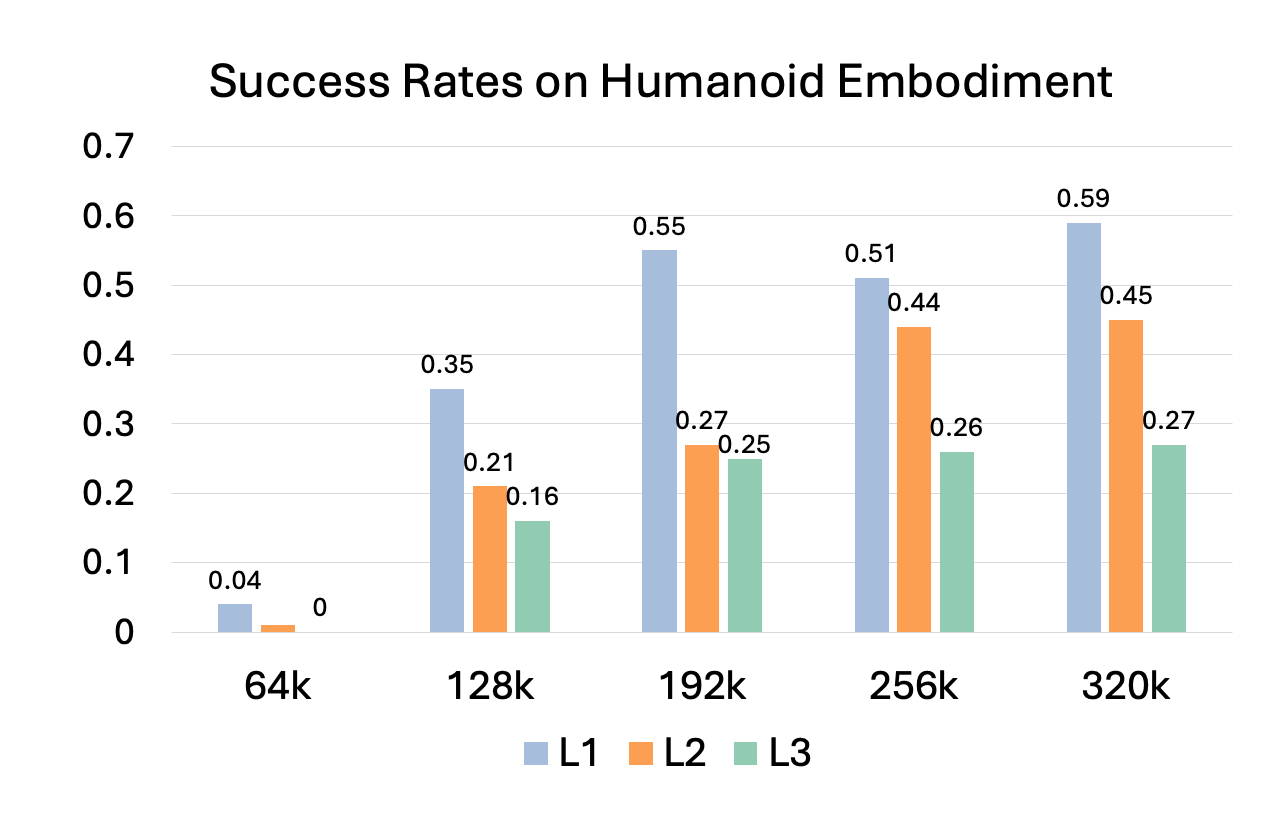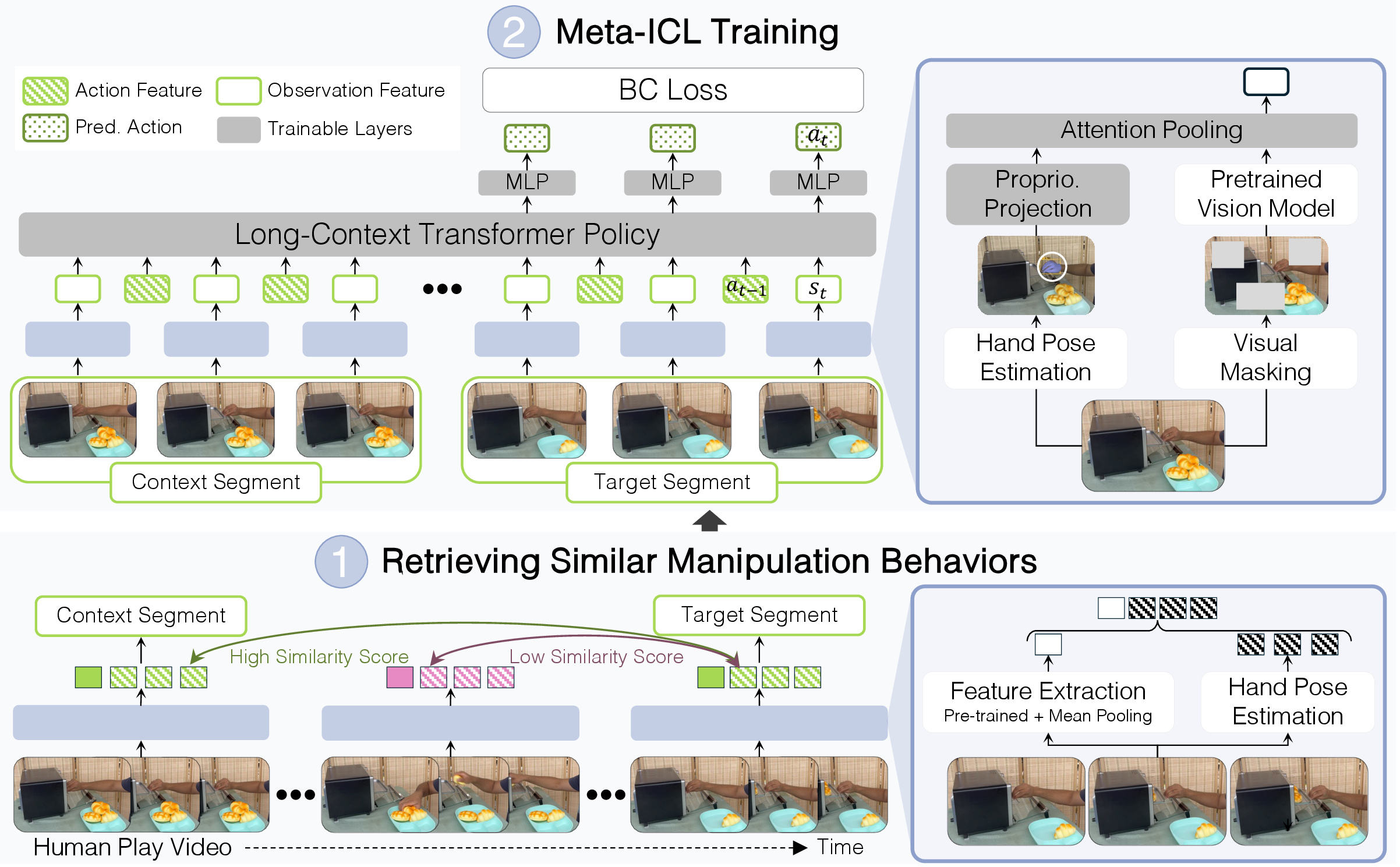
Our simulation benchmark evaluates few-shot learning across three progressively challenging levels:
- L1 (Seen Object, Seen Environment): Manipulation tasks with objects encountered during training in seen environments. This level evaluates the robot's ability to generalize to new object positions.
- L2 (Unseen Object, Seen Environment): Manipulation tasks with novel objects in seen environments. This level evaluates the robot's ability to adapt to novel objects using few demonstrations.
- L3 (Unseen Object, Unseen Environment): Manipulation tasks with novel objects in unseen environments. This level tests the robot's ability to generalize to different backgrounds, furniture layouts, and novel objects.
See details of simulation benchmark here
Baseline Comparisons
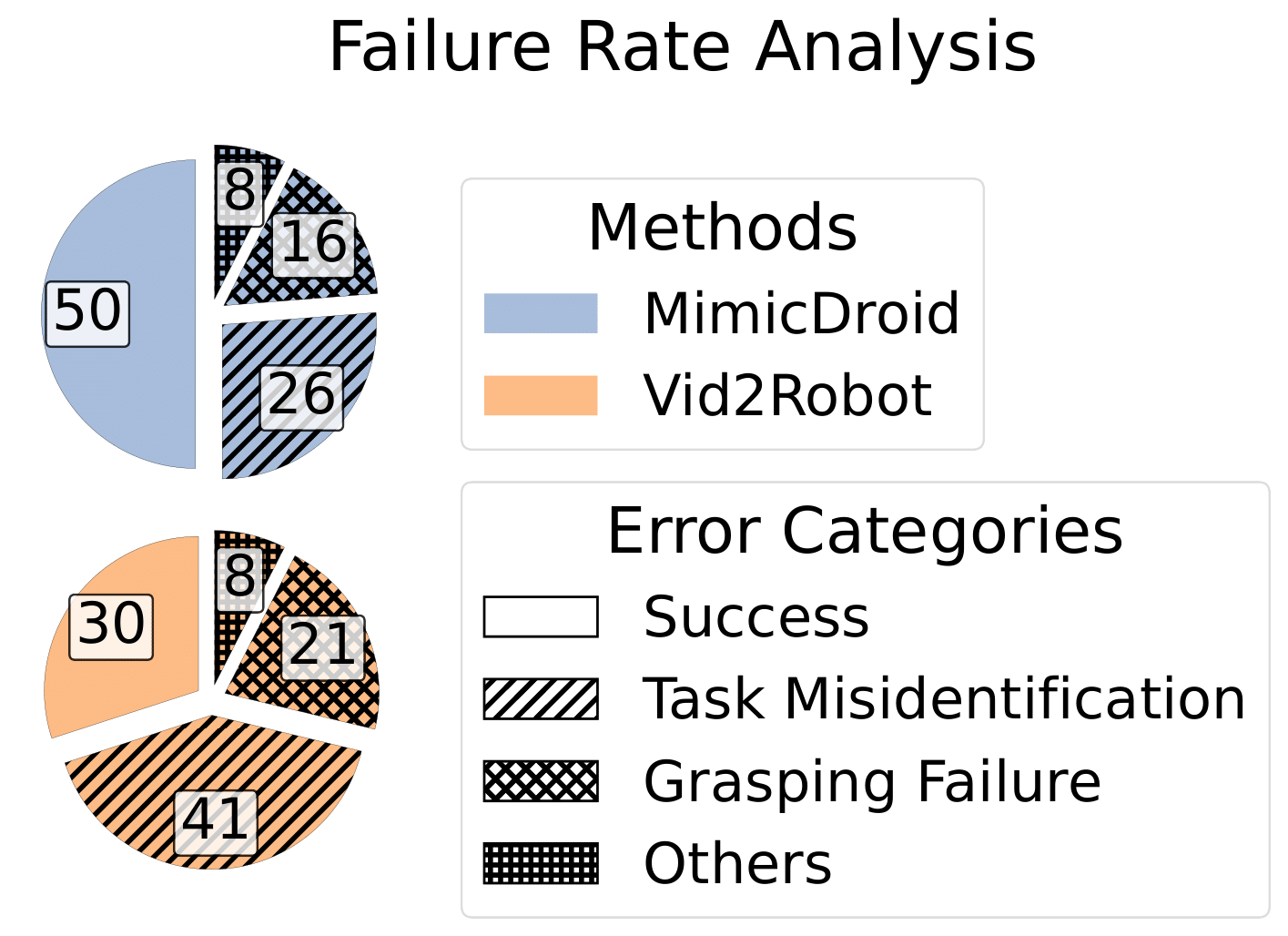
See qualitative videos of simulation rollouts here, and quantitative results below.
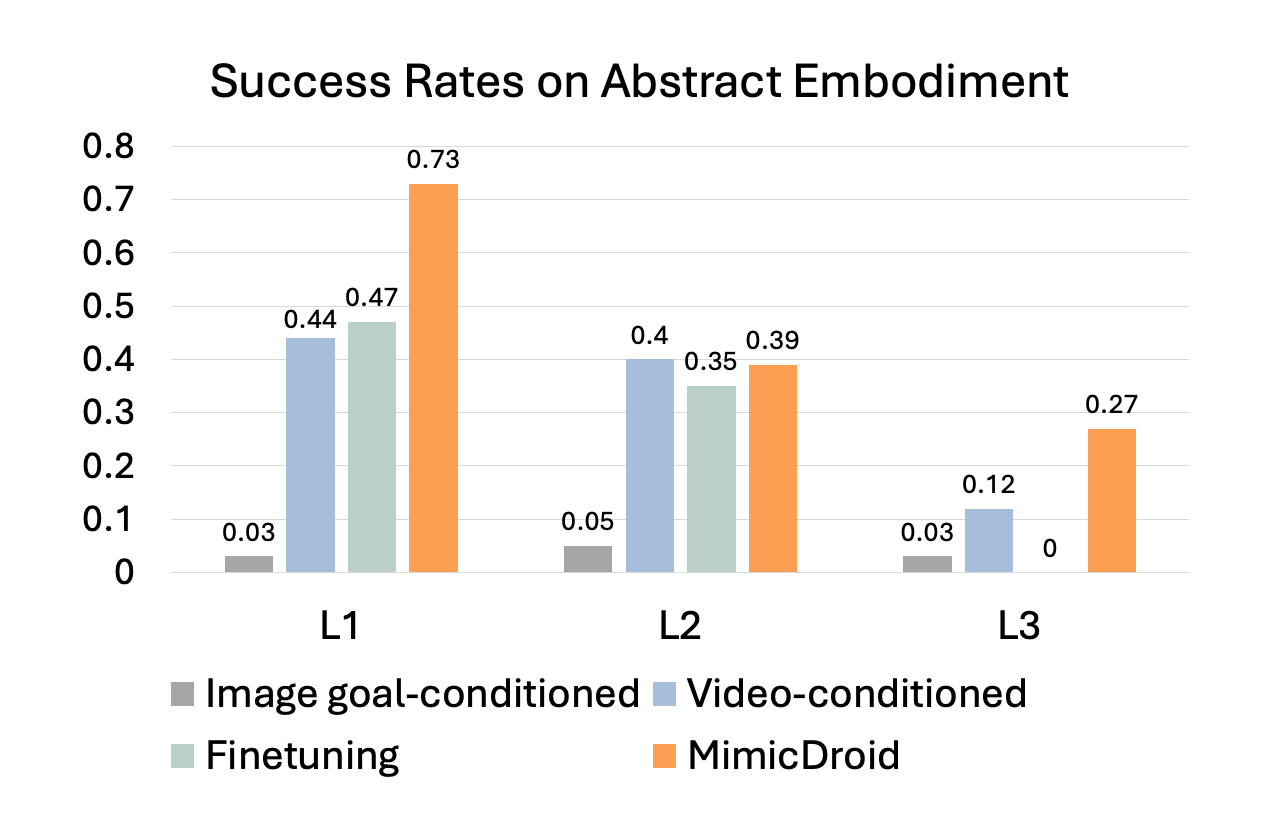
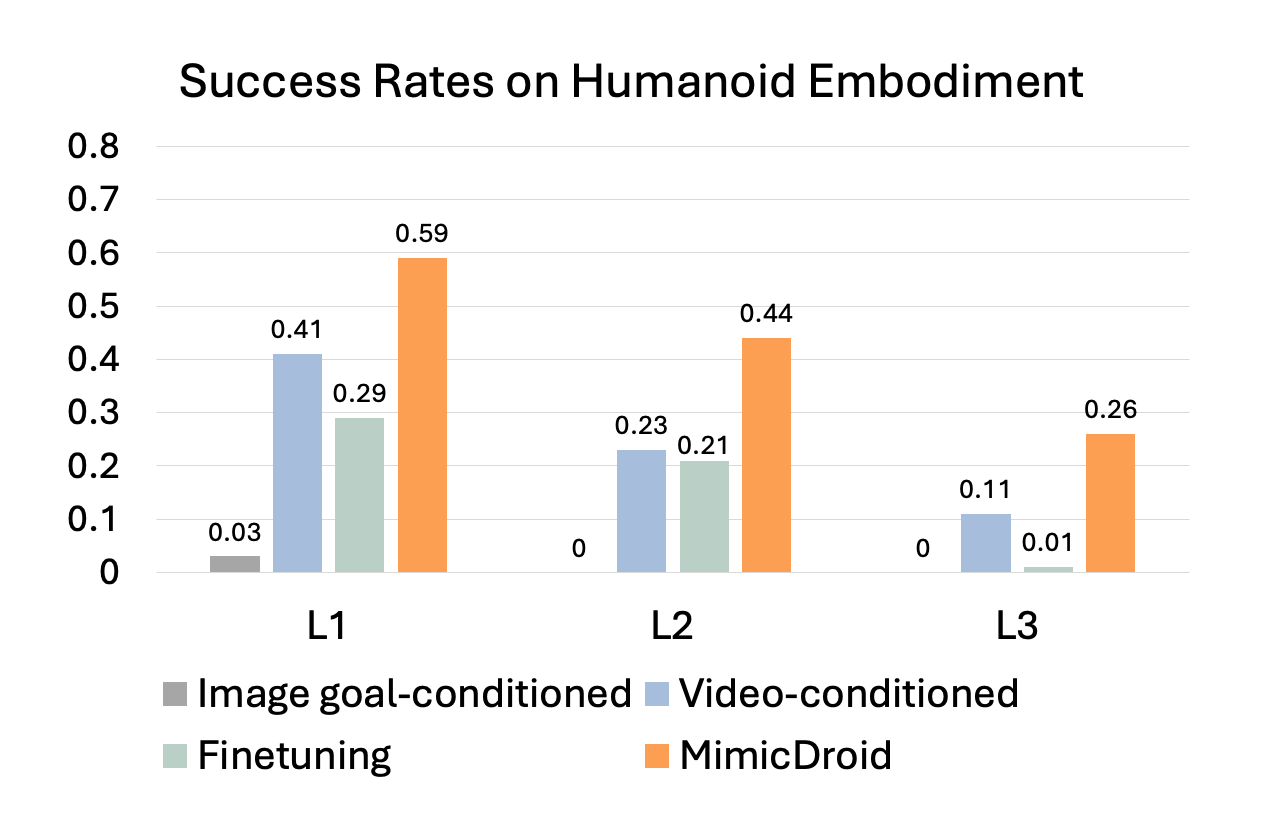
MimicDroid adapts instantly and robustly, outperforming test-time finetuning by 26% on the abstract embodiment and 29% on the humanoid embodiment, while incurring only a 3% drop across embodiments. In contrast, finetuning often overfits to the abstract embodiment, showing a larger 10% drop across embodiments, and suffers from catastrophic forgetting under distribution shifts, failing at the most challenging level (L3). Task-conditioned baselines that rely only on task specifications show lower performance by 14% on the abstract and 18% on the humanoid embodiment.