Learning and Retrieval from Prior Data
for Skill-based Imitation Learning
Soroush Nasiriany1 Tian Gao1,2 Ajay Mandlekar3 Yuke Zhu1
1The University of Texas at Austin 2IIIS, Tsinghua 3NVIDIA Research
Conference on Robot Learning (CoRL), 2022
Paper Code
|
Imitation learning offers a promising path for robots to learn general-purpose behaviors, but traditionally has exhibited limited scalability due to high data supervision requirements and brittle generalization. Inspired by recent advances in multi-task imitation learning, we investigate the use of prior data from previous tasks to facilitate learning novel tasks in a robust, data-efficient manner. To make effective use of the prior data, the robot must internalize knowledge from past experiences and contextualize this knowledge in novel tasks. To that end, we develop a skill-based imitation learning framework that extracts temporally extended sensorimotor skills from prior data and subsequently learns a policy for the target task that invokes these learned skills. We identify several key design choices that significantly improve performance on novel tasks, namely representation learning objectives to enable more predictable skill representations and a retrieval-based data augmentation mechanism to increase the scope of supervision for policy training. On a collection of simulated and real-world manipulation domains, we demonstrate that our method significantly outperforms existing imitation learning and offline reinforcement learning approaches. |
Method Overview
|
We present a skill-based imitation learning framework that uses prior data to effectively learn novel tasks. First, we learn a latent skill model on the prior data, with objectives to ensure a predictable skill representation. Given target task demonstrations, we use this latent space to retrieve similar behaviors from the prior data, expanding supervision for the policy. We then train a policy which outputs latent skills. |
Skill-based Imitation Learning Model
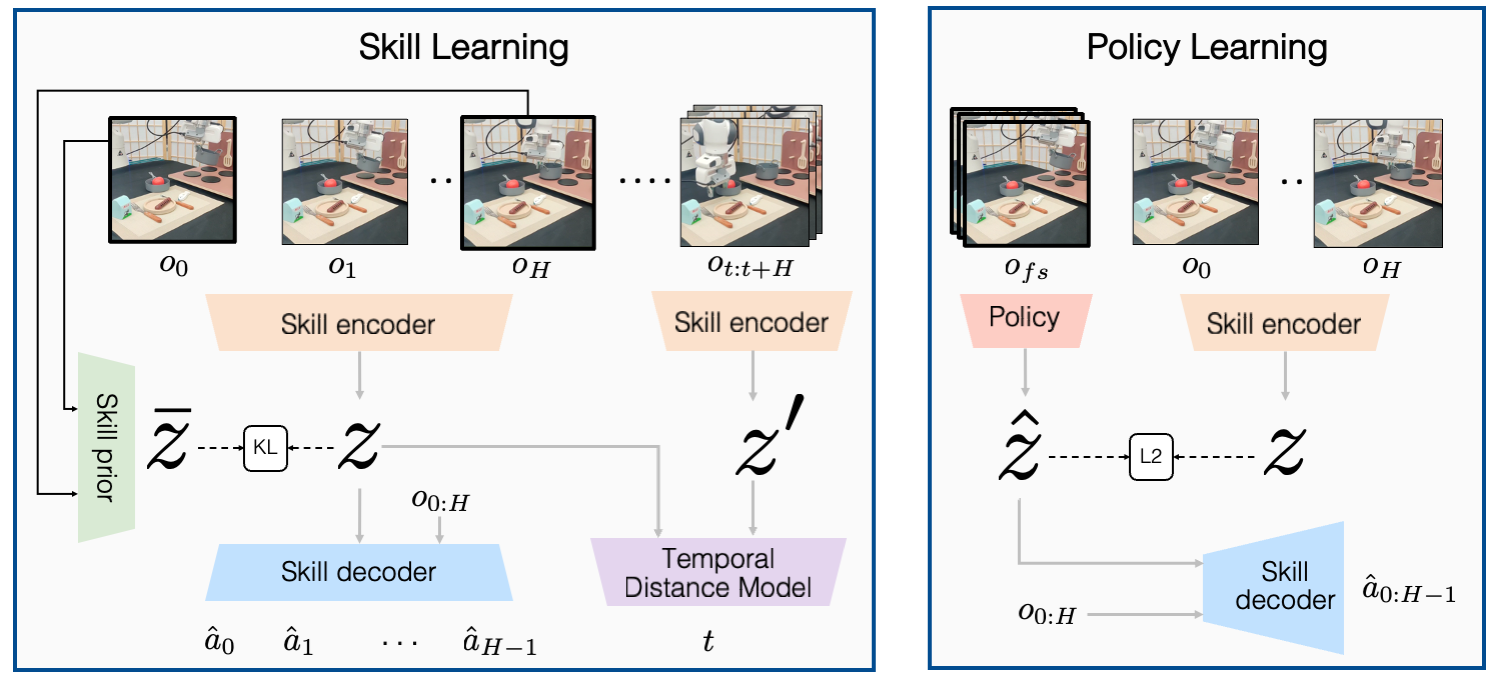 |
| Our method consists of a skill learning and policy learning phase. (left) In the skill learning phase we learn a latent skill representation of sub-trajectories in the prior dataset via a variational autoencoder, and we include an additional temporal predictability term to learn a more consistent latent representation. (right) In the policy learning phase we train the policy to predict the latent skill given a history of observations preceding the sub-trajectory. To execute the policy we decode the predicted latent using the skill decoder. We train the policy on sub-trajectories in the target task dataset in addition to retrieved sub-trajectories from the prior dataset. |
Simulated and Real-world Manipulation Domains
| We perform empirical evaluations on two simulated robot manipulation domains: (left) Franka Kitchen involves different sub-tasks, such as opening cabinets, moving a kettle, and turning on a stove. Our prior dataset contains demonstrations for different sub-tasks, and the target task involves a specific permutation of four sub-tasks. (right) CALVIN: playroom environment accompanied by task-agnostic “play” with diverse behaviors, such as opening and closing drawers, turning on and off the lights, and picking, placing, and pushing blocks. We consider two target tasks: setting up the table and cleaning up the table. |
Franka Kitchen |
CALVIN |
| We also evaluate our method in the real world with a kitchen environment involving eight food items, receptacles, a stove, and a serving area. We first collect a play dataset of exploratory interactions involving the food items and receptacles. For our target tasks, we consider setting up breakfast, and cooking a meal. |
Real Kitchen: Prior Data |
Real Kitchen: Target Tasks |
Simulation Results
| We evaluate our method against a set of six baselines and report the mean task success rate and standard deviation over three seeds (exception: six seeds for BC-RNN (FT) due to high variance). Note: for the kitchen tasks we report one number for baselines that do not involve prior data. We see that our method significantly outperforms the baselines on all tasks. |

| In our ablation study, we find that temporal predictability and retrieval are critical to skill-based imitation learning. In addition we validate that prior data plays a large role in the performance of our method. |

Real-World Evaluation
| We evaluate our method against the most competitive baseline, BC-RNN (FT). We find that while on the breakfast making task both methods achieve a success rate of 76.7%, on the cooking task our method significantly outperforms BC-RNN (FT) with a success rate of 76.7% vs. 46.7%: |
BC-RNN (FT): 46.7% |
Ours: 76.7% |
Citation
|
