Interactive Robot Learning from Verbal Correction
Huihan Liu1,2 Alice Chen1 Yuke Zhu2 Adith Swaminathan1 Andrey Kolobov1 Ching-An Cheng1
1Microsoft Research 2The University of Texas at Austin
Paper | Code | Bibtex
Abstract
|
The ability for robots to learn and refine behavior after deployment has become ever more important as we design them to operate in unstructured environments like households. In this work, we design a new learning system based on large language model (LLM), OLAF ☃️, that allows everyday users to teach a robot using verbal corrections when the robot makes mistakes, e.g., by saying "Stop what you're doing. You should move closer to the cup." A key feature of OLAF is its ability to update the robot's visuomotor neural policy based on the verbal feedback to avoid repeating mistakes in the future. This is in contrast to existing LLM-based robotic systems, which only follow verbal commands or corrections but not learn from them. We demonstrate the efficacy of our design in experiments where a user teaches a robot to perform long-horizon manipulation tasks both in simulation and on physical hardware, achieving on average 20.0% improvement in policy success rate. |
Overview
|
OLAF is a LLM-based learning system designed for updating a robot's visuomotor neural-network-based policy using verbal corrections given by regular non-expert users. To train the robot, the user simply needs to watch to robot performing a task, stop the robot when the user thinks the robot is not able to finish the task, and then provide an instruction in natural language on how the robot can do better. |
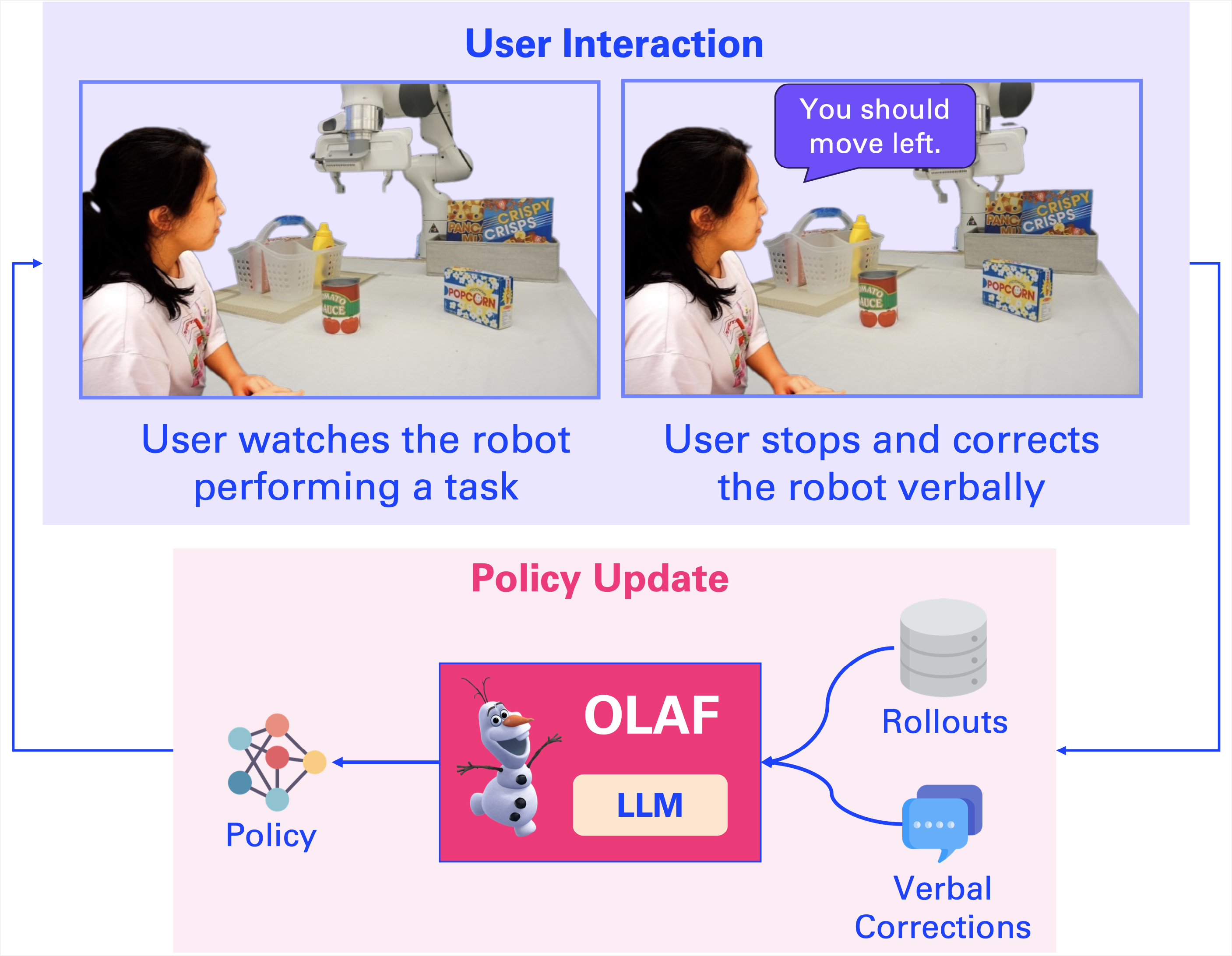
|
Motivating Example
|
We depicts an use case of OLAF for updating a robot manipulator's policy. Here the robot is tasked to place the tomato sauce in the basket. The robot opens its gripper and moves forward. But instead of going to the tomato sauce, it goes to the right. Upon seeing this surprising behavior, the user stops the robot by pressing a stop button and says "Stop. To pickup the tomato sauce, you should move to your left."
|
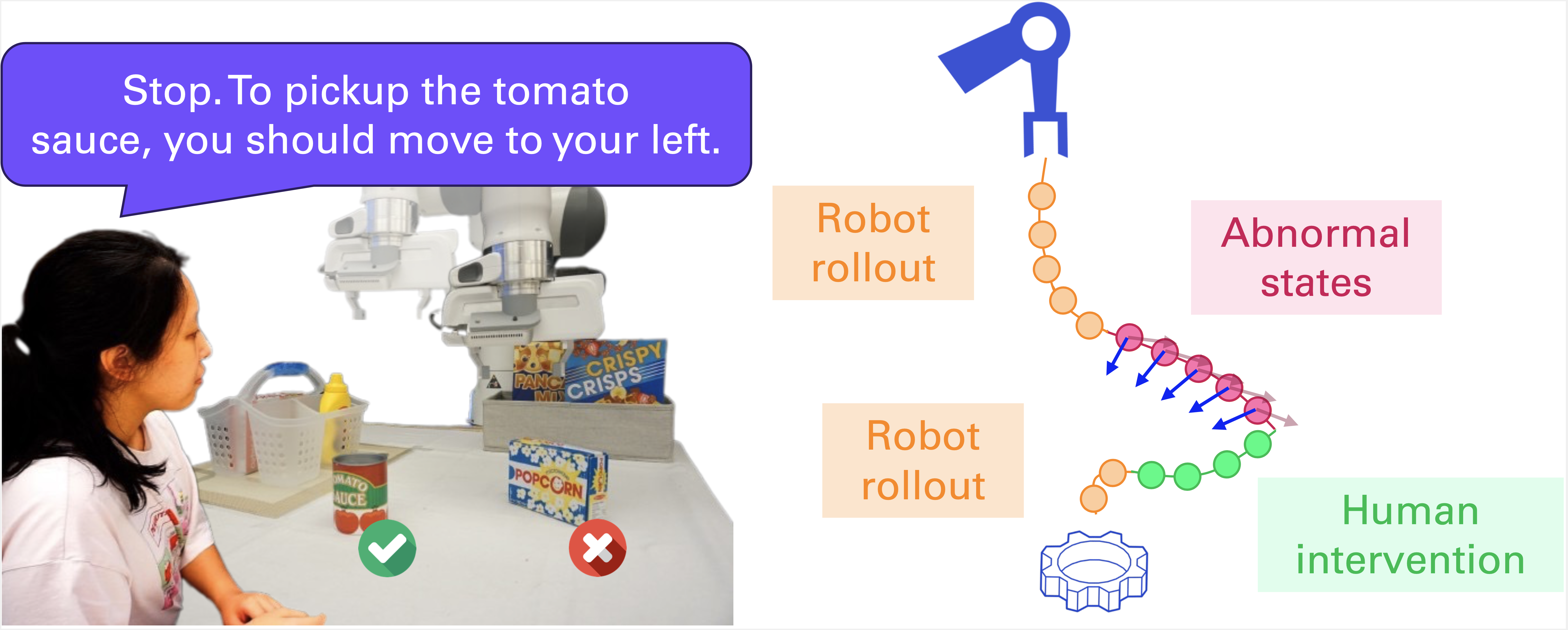
|
OLAF System
|
The OLAF pipeline consists of three steps: User Interaction, Data Synthesis, and Policy Update. In User Interaction, it collects pairs of {robot trajectory, verbal correction} of trajectories stopped by the user. In Data Synthesis, it uses the LLM as a critic to select the action (from a pool of action candidates) that best matches the user's verbal correction and relabels the pre-intervention trajectory segments (in red). In Policy Update, it updates the policy by performing behavior cloning on the newly synthesized data and the previously collected data. |
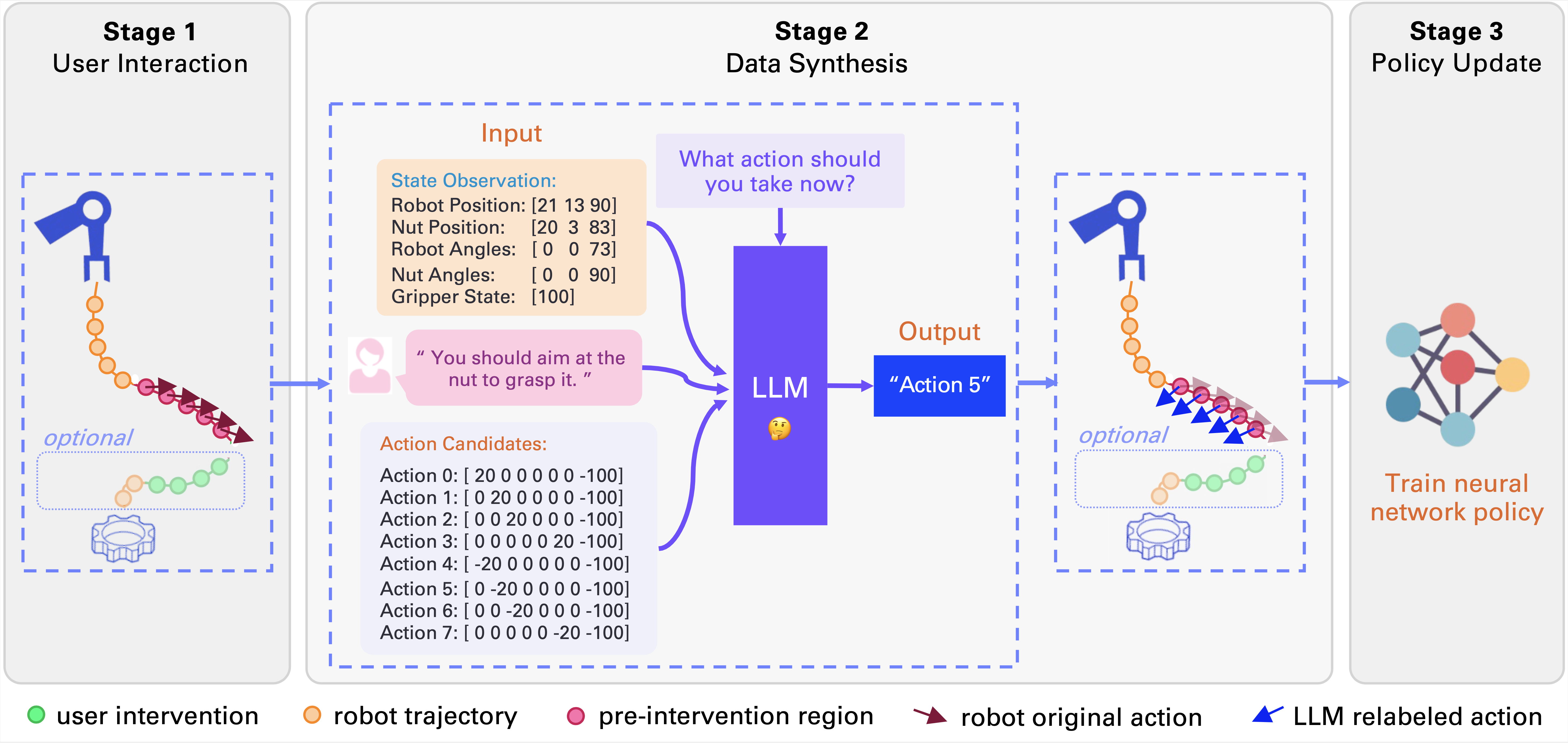
|
Tasks
|
We evaluate OLAF on four tasks in simulation and two tasks on real robot. The tasks in simulation are fine-grained manipulation tasks while the tasks on real robot are long-horizon, multi-staged tasks. |
Simulation
|
Pick Place Can |
Threading |
Square |
Coffee Machine |
Real Robot
|
PickPlace-Bin: |
PickPlace-Drawer-Basket: |
(played in 2X speed)
OLAF produces better quality policy behaviors
|
We show that OLAF helps the robot policy produce bette quality behaviors. Consider the case when the human intervention is available: while the BC baseline learn from data that corrects its behavior after it commits a mistake, OLAF with action relabeling learns what the robot could have done to avoid the mistakes in the first place. Overriding erroneous actions helps to learn the accurate actions that prevent the mistakes from happening, rather than merely recovering from the mistakes. |
|
BC baseline: BC learns the mistake actions, and then how to correct from the mistakes. It can sometimes still repeat the same mistakes. |
OLAF: OLAF directly learns the optimal behavior since action relabeling overrides wrong actions. |
Real Robot Evaluation Rollouts
|
We provide the real robot evaluation rollouts of OLAF and BC baseline to visualize the trajectory behavior and failure modes, as well as to present the entire evaluate process. All videos are played in 1X speed. |
OLAF: 73.5% Success Rate
BC: 35.3% Success Rate
Example Prompts
|
Prompts of an LLM as a critic for action relabeling: The system prompt (top) specify system-level desired behavior, the context prompt (middle) describes the task level instruction, and the action relabeling prompt (bottom) includes the trajectory-level information and the verbal correction. The black denotes the template and the blue denotes user- or sensor-dependent information. We highlight the action proposal in blue background. |
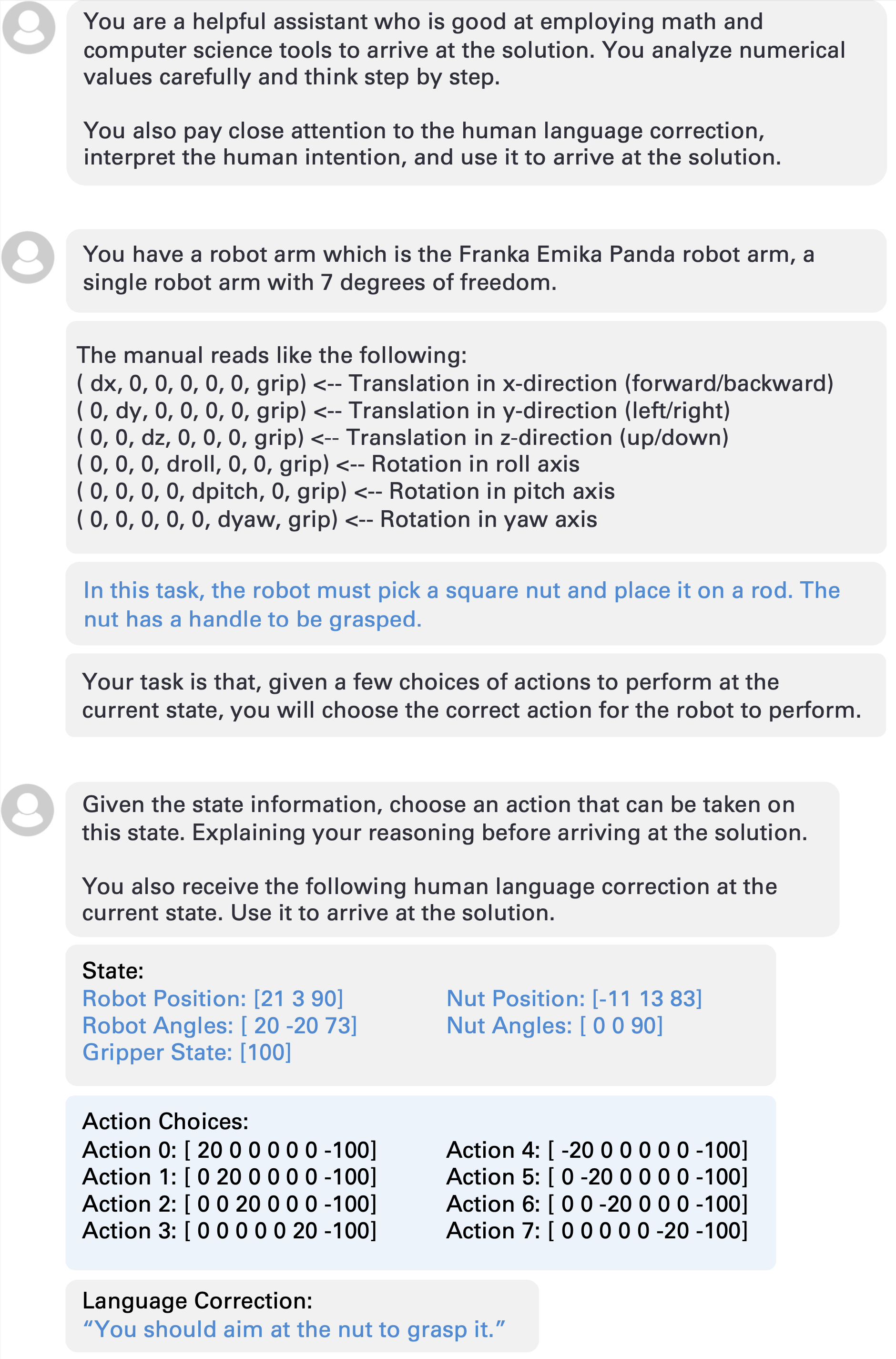
|
Citation
|